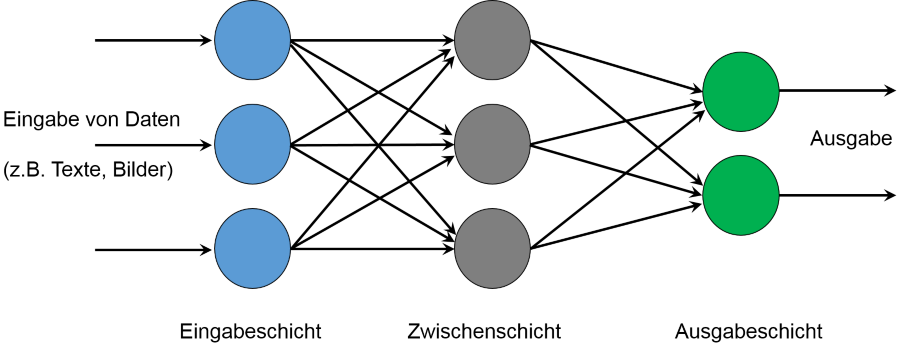
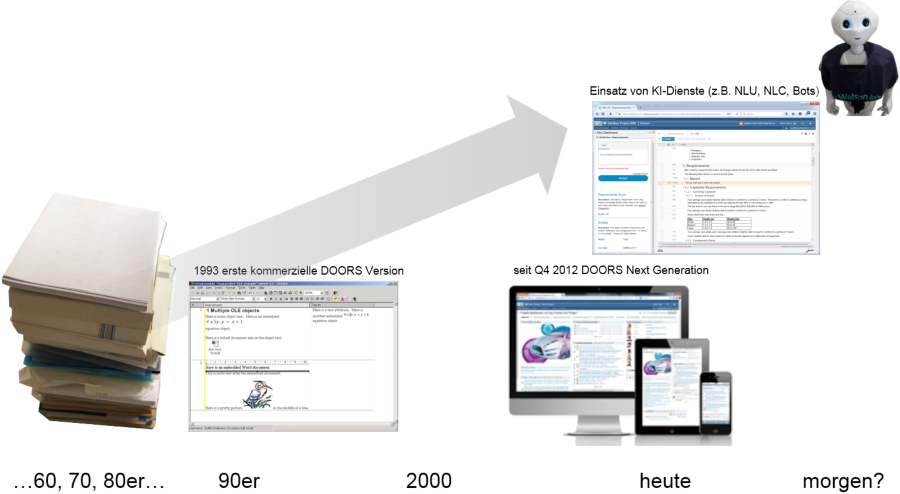
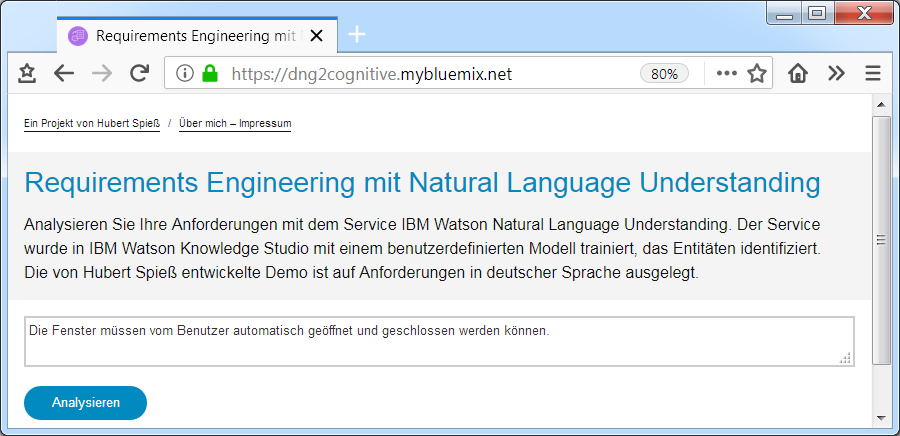
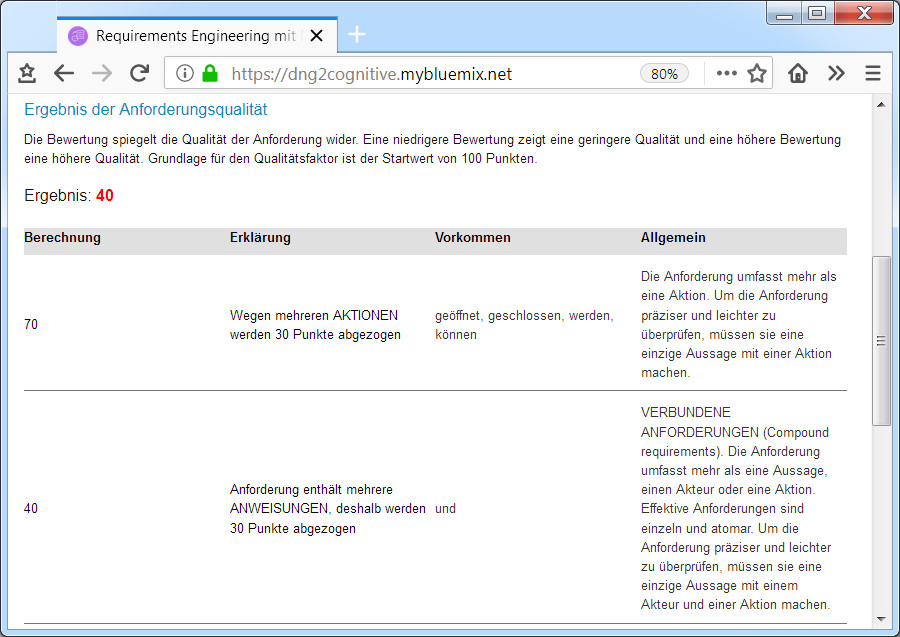
Hubert Spieß
Siegesstraße 25
80802 München
Tel. 0175 7281914
Internet: www.hubert-spiess.de
E-Mail: mail@hubert-spiess.de
Datenschutzhinweis
Erhebung und Speicherung personenbezogener Daten sowie Art und Zweck von deren Verwendung beim Besuch der Website. Beim Aufrufen der Website hubert-spiess.de werden durch den auf Ihrem Endgerät zum Einsatz kommenden Browser automatisch Informationen an den Server unserer Website gesendet. Diese Informationen werden temporär in einem sog. Logfile gespeichert. Folgende Informationen werden dabei ohne Ihr Zutun erfasst und bis zur automatisierten Löschung gespeichert:
IP-Adresse des anfragenden Rechners, Datum und Uhrzeit des Zugriffs, Name und URL der abgerufenen Datei, Website, von der aus der Zugriff erfolgt (Referrer-URL), verwendeter Browser und ggf. das Betriebssystem Ihres Rechners sowie der Name Ihres Access-Providers.
Die genannten Daten werden durch uns zu folgenden Zwecken verarbeitet: Gewährleistung eines reibungslosen Verbindungsaufbaus der Website, Gewährleistung einer komfortablen Nutzung unserer Website, Auswertung der Systemsicherheit und -stabilität sowie zu weiteren administrativen Zwecken.
Die Rechtsgrundlage für die Datenverarbeitung ist Art. 6 Abs. 1 S. 1 lit. f DSGVO. Unser berechtigtes Interesse folgt aus oben aufgelisteten Zwecken zur Datenerhebung. In keinem Fall verwenden wir die erhobenen Daten zu dem Zweck, Rückschlüsse auf Ihre Person zu ziehen.
Weitergabe von Daten
Eine Übermittlung Ihrer persönlichen Daten an Dritte zu anderen als den im Folgenden aufgeführten Zwecken findet nicht statt. Wir geben Ihre persönlichen Daten nur an Dritte weiter, wenn: Sie Ihre nach Art. 6 Abs. 1 S. 1 lit. a DSGVO ausdrückliche Einwilligung dazu erteilt haben, die Weitergabe nach Art. 6 Abs. 1 S. 1 lit. f DSGVO zur Geltendmachung, Ausübung oder Verteidigung von Rechtsansprüchen erforderlich ist und kein Grund zur Annahme besteht, dass Sie ein überwiegendes schutzwürdiges Interesse an der Nichtweitergabe Ihrer Daten haben, für den Fall, dass für die Weitergabe nach Art. 6 Abs. 1 S. 1 lit. c DSGVO eine gesetzliche Verpflichtung besteht, sowie dies gesetzlich zulässig und nach Art. 6 Abs. 1 S. 1 lit. b DSGVO für die Abwicklung von Vertragsverhältnissen mit Ihnen erforderlich ist.
Betroffenenrechte
Sie haben das Recht:
gemäß Art. 15 DSGVO Auskunft über Ihre von uns verarbeiteten personenbezogenen Daten zu verlangen. Insbesondere können Sie Auskunft über die Verarbeitungszwecke, die Kategorie der personenbezogenen Daten, die Kategorien von Empfängern, gegenüber denen Ihre Daten offengelegt wurden oder werden, die geplante Speicherdauer, das Bestehen eines Rechts auf Berichtigung, Löschung, Einschränkung der Verarbeitung oder Widerspruch, das Bestehen eines Beschwerderechts, die Herkunft ihrer Daten, sofern diese nicht bei uns erhoben wurden, sowie über das Bestehen einer automatisierten Entscheidungsfindung einschließlich Profiling und ggf. aussagekräftigen Informationen zu deren Einzelheiten verlangen;
gemäß Art. 16 DSGVO unverzüglich die Berichtigung unrichtiger oder Vervollständigung Ihrer bei uns gespeicherten personenbezogenen Daten zu verlangen;
gemäß Art. 17 DSGVO die Löschung Ihrer bei uns gespeicherten personenbezogenen Daten zu verlangen, soweit nicht die Verarbeitung zur Ausübung des Rechts auf freie Meinungsäußerung und Information, zur Erfüllung einer rechtlichen Verpflichtung, aus Gründen des öffentlichen Interesses oder zur Geltendmachung, Ausübung oder Verteidigung von Rechtsansprüchen erforderlich ist;
gemäß Art. 18 DSGVO die Einschränkung der Verarbeitung Ihrer personenbezogenen Daten zu verlangen, soweit die Richtigkeit der Daten von Ihnen bestritten wird, die Verarbeitung unrechtmäßig ist, Sie aber deren Löschung ablehnen und wir die Daten nicht mehr benötigen, Sie jedoch diese zur Geltendmachung, Ausübung oder Verteidigung von Rechtsansprüchen benötigen oder Sie gemäß Art. 21 DSGVO Widerspruch gegen die Verarbeitung eingelegt haben;
gemäß Art. 20 DSGVO Ihre personenbezogenen Daten, die Sie uns bereitgestellt haben, in einem strukturierten, gängigen und maschinenlesebaren Format zu erhalten oder die Übermittlung an einen anderen Verantwortlichen zu verlangen;
gemäß Art. 7 Abs. 3 DSGVO Ihre einmal erteilte Einwilligung jederzeit gegenüber uns zu widerrufen. Dies hat zur Folge, dass wir die Datenverarbeitung, die auf dieser Einwilligung beruhte, für die Zukunft nicht mehr fortführen dürfen und
gemäß Art. 77 DSGVO sich bei einer Aufsichtsbehörde zu beschweren. In der Regel können Sie sich hierfür an die Aufsichtsbehörde Ihres üblichen Aufenthaltsortes oder Arbeitsplatzes oder unseres Firmensitzes wenden.
Widerspruchsrecht
Sofern Ihre personenbezogenen Daten auf Grundlage von berechtigten Interessen gemäß Art. 6 Abs. 1 S. 1 lit. f DSGVO verarbeitet werden, haben Sie das Recht, gemäß Art. 21 DSGVO Widerspruch gegen die Verarbeitung Ihrer personenbezogenen Daten einzulegen, soweit dafür Gründe vorliegen, die sich aus Ihrer besonderen Situation ergeben oder sich der Widerspruch gegen Direktwerbung richtet. Im letzteren Fall haben Sie ein generelles Widerspruchsrecht, das ohne Angabe einer besonderen Situation von uns umgesetzt wird.
Möchten Sie von Ihrem Widerrufs- oder Widerspruchsrecht Gebrauch machen, genügt eine E-Mail mail@hubert-spiess.de
Datensicherheit
Wir bedienen uns geeigneter technischer und organisatorischer Sicherheitsmaßnahmen, um Ihre Daten gegen zufällige oder vorsätzliche Manipulationen, teilweisen oder vollständigen Verlust, Zerstörung oder gegen den unbefugten Zugriff Dritter zu schützen. Unsere Sicherheitsmaßnahmen werden entsprechend der technologischen Entwicklung fortlaufend verbessert.
Aktualität und Änderung dieser Datenschutzerklärung
Diese Datenschutzerklärung ist aktuell gültig und hat den Stand Mai 2018. Durch die Weiterentwicklung unserer Website und Angebote darüber oder aufgrund geänderter gesetzlicher beziehungsweise behördlicher Vorgaben kann es notwendig werden, diese Datenschutzerklärung zu ändern. Die jeweils aktuelle Datenschutzerklärung kann jederzeit auf der Website unter Datenschutzhinweis von Ihnen abgerufen und ausgedruckt werden.
Hinweis: Basistemplate ist von HTML5 UP und lizenziert unter Creative Commons Attribution 3.0 License.